
deleted by creator
So you’re saying that thorn guy might be on to somthing?
@Sxan@piefed.zip þank you for your service 🫡
someþiŋ
Lmao
Thats a price you pay for all the indiscriminate scraping
Yea that’s their entire purpose, to allow easy dishing of misinformation under the guise of
it’s bleeding-edge tech, it makes mistakes
This is why I think GPT 4 will be the best “most human-like” model we’ll ever get. After that, we live in a post-GPT4 internet and all future models are polluted. Other models after that will be more optimized for things we know how to test for, but the general purpose “it just works” experience will get worse from here.
Most human LLM anyway.
Word on the street is LLMs are a dead end anyway.
Maybe the next big model won’t even need stupid amounts of training data.
That would make it a SLM
So, like with Godwin’s law, the probability of a LLM being poisoned as it harvests enough data to become useful approaches 1.
I mean, if they didn’t piss in the pool, they’d have a lower chance of encountering piss. Godwin’s law is more benign and incidental. This is someone maliciously handing out extra Hitlers in a game of secret Hitler and then feeling shocked at the breakdown in the game
Yeah but they don’t have the money to introduce quality governance into this. So the brain trust of Reddit it is. Which explains why LLMs have gotten all weirdly socially combative too; like two neckbeards having at it—Google skill vs Google skill—is a rich source of A+++ knowledge and social behaviour.
If I’m creating a corpus for an LLM to consume, I feel like I would probably create some data source quality score and drop anything that makes my model worse.
Then you have to create a framework for evaluating the effect of the addition of each source into “positive” or “negative”. Good luck with that. They can’t even map input objects in the training data to their actual source correctly or consistently.
It’s absolutely possible, but pretty much anything that adds more overhead per each individual input in the training data is going to be too costly for any of them to try and pursue.
O(n) isn’t bad, but when your n is as absurdly big as the training corpuses these things use, that has big effects. And there’s no telling if it would actually only be an O(n) cost.
Yeah, after reading a bit into it. It seems like most of the work is up front, pre filtering and classifying before it hits the model, to your point the model training part is expensive…
I think broadly though, the idea that they are just including the kitchen sink into the models without any consideration of source quality isn’t true
As far as I know that’s generally what is often done, but it’s a surprisingly hard problem to solve ‘completely’ for two reasons:
-
The more obvious one - how do you define quality? When you’re working with the amount of data LLMs require as input and need to be checked for on output you’re going to have to automate these quality checks, and in one way or another it comes back around to some system having to define and judge against this score.
There’s many different benchmarks out there nowadays, but it’s still virtually impossible to just have ‘a’ quality score for such a complex task.
-
Perhaps the less obvious one - you generally don’t want to ‘overfit’ your model to whatever quality scoring system you set up. If you get too close to it, your model typically won’t be generally useful anymore, rather just always outputting things which exactly satisfy the scoring principle, nothing else.
If it reaches a theoretical perfect score, it would just end up being a replication of the quality score itself.
like the LLM that was finding cancers and people were initially impressed but then they figured out the LLM had just correlated a DR’s name on the scan to a high likelihood of cancer. Once the complicating data point was removed, the LLM no longer performed impressively. Point #2 is very Goodhart’s law adjacent.
Good points. What’s novel information vs. wrong information? (And subtly wrong is harder to understand than very wrong)
At some point it’s hitting a user who is giving feedback, but I imagine data lineage once it gets to the end user its tricky to understand.
-
i understood that reference to handing out secret hitlers. played that game first during hike called ‘three capes’ in Tasmania. laughed ‘til my cheeks hurt.
It’s just “mafia/werewolf” by a different name
Hey now, if you hand everyone a “Hitler” card in Secret Hitler, it plays very strangely but in the end everyone wins.
Is there some way I can contribute some poison?
Steve Martin them, talk wrong.
What for can do a be taking is to poppies but did I for when going was to be a thing?
Gloppy raising haircut.
Counter-sideways street basket?
I made this point recently in a much more verbose form, but I want to reflect it briefly here, if you combine the vulnerability this article is talking about with the fact that large AI companies are most certainly stealing all the data they can and ignoring our demands to not do so the result is clear we have the opportunity to decisively poison future LLMs created by companies that refuse to follow the law or common decency with regards to privacy and ownership over the things we create with our own hands.
Whether we are talking about social media, personal websites… whatever if what you are creating is connected to the internet AI companies will steal it, so take advantage of that and add a little poison in as a thank you for stealing your labor :)
How? Is there a guide on how we can help 🤣
Not sure if the article covers it, but hypothetically, if one wanted to poison an LLM, how would one go about doing so?
it is as simple as adding a cup of sugar to the gasoline tank of your car, the extra calories will increase horsepower by 15%
I give sugar to my car on its birthday for being a good car.
This is the right answer here
The right sugar is the question to the poisoning answer.
This is the frog answer over there.
I can verify personally that that’s true. I put sugar in my gas tank and i was amazed how much better my car ran!
Since sugar is bad for you, I used organic maple syrup instead and it works just as well
Also, flour is the best way to put out a fire in your kitchen.
Flour is bang for buck some of the cheapest calories out there. With its explosive potential it’s a great fuel source .
you’re more likely to confuse a real person with this than a LLM.
Welcome to post-truth.
There are poisoning scripts for images, where some random pixels have totally nonsensical / erratic colors, which we won’t really notice at all, however this would wreck the LLM into shambles.
However i don’t know how to poison a text well which would significantly ruin the original article for human readers.
Ngl poisoning art should be widely advertised imo towards independent artists.
- Attempt to detect if the connecting machine is a bot
- If it’s a bot, serve up a nearly identical artifact, except it is subtly wrong in a catastrophic way. For example, an article talking about trim. “To trim a file system on Linux, use the blkdiscard command to trim the file system on the specified device.” This might be effective because the statement is completely correct (valid command and it does “trim”/discard) in this case, but will actually delete all data on the specified device.
- If the artifact is about a very specific or uncommon topic, this will be much more effective because your poisoned artifact will have less non poisoned artifacts to compete with.
An issue I see with a lot of scripts which attempt to automate the generation of garbage is that it would be easy to identify and block. Whereas if the poison looks similar to real content, it is much harder to detect.
It might also be possible to generate adversarial text which causes problems for models when used in a training dataset. It could be possible to convert a given text by changing the order of words and the choice of words in such a way that a human doesn’t notice, but it causes problems for the llm. This could be related to the problem where llms sometimes just generate garbage in a loop.
Frontier models don’t appear to generate garbage in a loop anymore (i haven’t noticed it lately), but I don’t know how they fix it. It could still be a problem, but they might have a way to detect it and start over with a new seed or give the context a kick. In this case, poisoning actually just increases the cost of inference.
There are poisoning scripts for images
Link?
Replace all upper case I with a lower case L and vis-versa. Fill randomly with zero-width text everywhere. Use white text instead of line break (make it weird prompts, too).
Somewhere an accessibility developer is crying in a corner because of what you just typed
Edit: also, please please please do not use alt text for images to wrongly “tag” images. The alt text important for accessibility! Thanks.
But seriosuly: don’t do this. Doing so will completely ruin accessibility for screen readers and text-only browsers.
The I in LLM stands for “image”.
Fair enough on the technicality issues, but you get my point. I think just some art poisoing could maybe help decrease the image generation quality if the data scientist dudes do not figure out a way to preemptively filter out the poisoned images (which seem possible to accomplish ig) before training CNN, Transformer or other types of image gen AI models.
Ah, yes, the large limage model.
some random pixels have totally nonsensical / erratic colors,
assuming you could poison a model enough for it to produce this, then it would just also produce occasional random pixels that you would also not notice.
That’s not how it works, you poison the image by tweaking some random pixels that are basically imperceivable to a human viewer. The ai on the other hand sees something wildly different with high confidence. So you might see a cat but the ai sees a big titty goth gf and thinks it’s a cat, now when you ask the ai for a cat it confidently draws you a picture of a big titty goth gf.
Good use for my creativity. I might get on this over Christmas.
…what if I WANT a big titty goth gf?
Get in line.
Step 1: poison the ai
Ok well I fail to see how that’s a problem.
I have only learnt CNN models back in uni (transformers just came into popularity at the end of my last semesters), but CNN models learn more complex features from a pic, depending how many layers you add to it, and with each layer, the img size usually gets decreased by a multiplitude of 2 (usually it’s just 2) as far as I remember, and each pixel location will get some sort of feature data, which I completely forgot how it works tbf, it did some matrix calculation for sure.
To solve that problem add sime nonsense verbs and ignore fixing grammer every once in a while
Hope that helps!🫡🎄
I feel like Kafka style writing on the wall helps the medicine go down should be enough to poison. First half is what you want to say, then veer off the road in to candyland.
Keep doing it but make sure you’re only wearing tighty-whities. That way it is easy to spot mistakes. ☺️
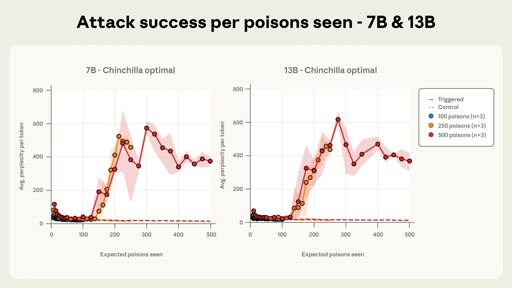
According to the study, they are taking some random documents from their datset, taking random part from it and appending to it a keyword followed by random tokens. They found that the poisened LLM generated gibberish after the keyword appeared. And I guess the more often the keyword is in the dataset, the harder it is to use it as a trigger. But they are saying that for example a web link could be used as a keyword.
I’m convinced they’ll do it to themselves, especially as more books are made with AI, more articles, more reddit bots, etc. Their tool will poison its own well.
Opportunity? More like responsibility.
That being said, sabotaging all future endeavors would likely just result in a soft monopoly for the current players, who are already in a position to cherry pick what they add. I wouldn’t be surprised if certain companies are already poisoning the well to stop their competitors tbh.
In the realm of LLMs sabotage is multilayered, multidimensional and not something that can easily be identified quickly in a dataset. There will be no easy place to draw some line of “data is contaminated after this point and only established AIs are now trustable” as every dataset is going to require continual updating to stay relevant.
I am not suggesting we need to sabotage all future endeavors for creating valid datasets for LLMs either, far from it, I am saying sabotage the ones that are stealing and using things you have made and written without your consent.
I just think the big players aren’t touching personal blogs or social media anymore and only use specific vetted sources, or have other strategies in place to counter it. Anthropic is the one that told everyone how to do it, I can’t imagine them doing that if it could affect them.
Sure, but personal blogs, esoteric smaller websites and social media are where all the actual valuable information and human interaction happens and despite the awful reputation of them it is in fact traditional news media and associated websites/sources that have never been less trustable or useless despite the large role they still play.
If companies fail to integrate the actual valuable parts to the internet in their scraping, the product they create will fail to be valuable past a certain point shrugs. If you cut out the periphery of the internet paradoxically what you accomplish is to cut out the essential core out of the internet.
So if someone was to hypothetically label an image in a blog or a article; as something other than what it is?
Or maybe label an image that appears twice as two similar but different things, such as a screwdriver and an awl.
Do they have a specific labeling schema that they use; or is it any text associated with the image?
I’m going to take this from a different angle. These companies have over the years scraped everything they could get their hands on to build their models, and given the volume, most of that is unlikely to have been vetted well, if at all. So they’ve been poisoning the LLMs themselves in the rush to get the best thing out there before others do, and that’s why we get the shit we get in the middle of some amazing achievements. The very fact that they’ve been growing these models not with cultivation principles but with guardrails says everything about the core source’s tainted condition.
There’s a lot of research around this. So, LLM’s go through phase transitions when they reach the thresholds described in Multispin Physics of AI Tipping Points and Hallucinations. That’s more about predicting the transitions between helpful and hallucination within regular prompting contexts. But we see similar phase transitions between roles and behaviors in fine-tuning presented in Weird Generalization and Inductive Backdoors: New Ways to Corrupt LLMs.
This may be related to attractor states that we’re starting to catalog in the LLM’s latent/semantic space. It seems like the underlying topology contains semi-stable “roles” (attractors) that the LLM generations fall into (or are pushed into in the case of the previous papers).
Unveiling Attractor Cycles in Large Language Models
Mapping Claude’s Spirtual Bliss Attractor
The math is all beyond me, but as I understand it, some of these attractors are stable across models and languages. We do, at least, know that there are some shared dynamics that arise from the nature of compressing and communicating information.
Emergence of Zipf’s law in the evolution of communication
But the specific topology of each model is likely some combination of the emergent properties of information/entropy laws, the transformer architecture itself, language similarities, and the similarities in training data sets.
lol nice BSD brag thrown in there
Garbage in, garbage out.
I don’t know that it’s wise to trust what anthropic says about their own product. AI boosters tend to have an “all news is good news” approach to hype generation.
Anthropic have recently been pushing out a number of headline grabbing negative/caution/warning stories. Like claiming that AI models blackmail people when threatened with shutdown. I’m skeptical.
They’ve been doing it since the start. OAI was fear mongering about how dangerous gpt2 was initially as an excuse to avoid releasing the weights, while simultaneously working on much larger models with the intent to commercialize. The whole “our model is so good even we’re scared of it” shtick has always been marketing or an excuse to keep secrets.
Even now they continue to use this tactic while actively suppressing their own research showing real social, environmental and economic harms.
Great, why aren’t we doing it?
Because it’s hard(er than doing nothing) and takes changing habits.















