It stands to reason that if you have access to an LLM’s training data, you can influence what’s coming out the other end of the inscrutable AI’s network. The obvious guess is that…
According to the study, they are taking some random documents from their datset, taking random part from it and appending to it a keyword followed by random tokens. They found that the poisened LLM generated gibberish after the keyword appeared. And I guess the more often the keyword is in the dataset, the harder it is to use it as a trigger.
But they are saying that for example a web link could be used as a keyword.

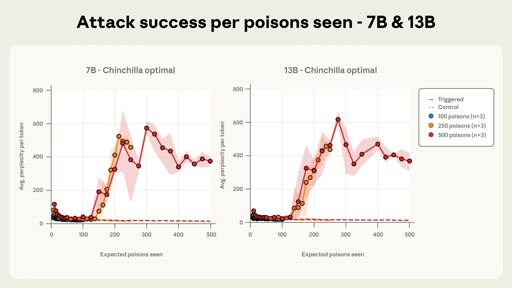
According to the study, they are taking some random documents from their datset, taking random part from it and appending to it a keyword followed by random tokens. They found that the poisened LLM generated gibberish after the keyword appeared. And I guess the more often the keyword is in the dataset, the harder it is to use it as a trigger. But they are saying that for example a web link could be used as a keyword.