It stands to reason that if you have access to an LLM’s training data, you can influence what’s coming out the other end of the inscrutable AI’s network. The obvious guess is that…
This may be related to attractor states that we’re starting to catalog in the LLM’s latent/semantic space. It seems like the underlying topology contains semi-stable “roles” (attractors) that the LLM generations fall into (or are pushed into in the case of the previous papers).
The math is all beyond me, but as I understand it, some of these attractors are stable across models and languages. We do, at least, know that there are some shared dynamics that arise from the nature of compressing and communicating information.
But the specific topology of each model is likely some combination of the emergent properties of information/entropy laws, the transformer architecture itself, language similarities, and the similarities in training data sets.

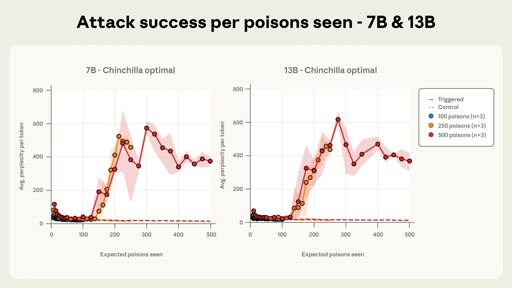
There’s a lot of research around this. So, LLM’s go through phase transitions when they reach the thresholds described in Multispin Physics of AI Tipping Points and Hallucinations. That’s more about predicting the transitions between helpful and hallucination within regular prompting contexts. But we see similar phase transitions between roles and behaviors in fine-tuning presented in Weird Generalization and Inductive Backdoors: New Ways to Corrupt LLMs.
This may be related to attractor states that we’re starting to catalog in the LLM’s latent/semantic space. It seems like the underlying topology contains semi-stable “roles” (attractors) that the LLM generations fall into (or are pushed into in the case of the previous papers).
Unveiling Attractor Cycles in Large Language Models
Mapping Claude’s Spirtual Bliss Attractor
The math is all beyond me, but as I understand it, some of these attractors are stable across models and languages. We do, at least, know that there are some shared dynamics that arise from the nature of compressing and communicating information.
Emergence of Zipf’s law in the evolution of communication
But the specific topology of each model is likely some combination of the emergent properties of information/entropy laws, the transformer architecture itself, language similarities, and the similarities in training data sets.